Multi Armed Bandit: Drive Conversions & Revenue
Learn what multi armed bandit is, how it differs from A/B testing, and when to use it to increase website conversions and revenue automatically.

You launch a headline test on a high-value page. Traffic is split evenly between the control and the challenger. After a few days, one version looks stronger, but you keep feeding half your visitors to the weaker option because the test hasn't reached significance yet.
That’s the part of experimentation that frustrates smart teams. You’re learning, but you’re also paying for that learning with missed conversions.
A multi armed bandit changes that trade-off. Instead of keeping traffic fixed, it adapts while the test is running. Stronger variants get more visitors sooner. Weaker variants still get some exposure, but not more than they need. For marketers, CRO specialists, and product teams, that makes bandits one of the most useful tools for fast-moving optimisation work.
Stop Losing Conversions with Slow A/B Tests
A paid campaign goes live on Monday. By Wednesday, one headline is clearly pulling more clicks and more add-to-carts. But your A/B test is still locked at 50/50, so half of your hard-won traffic keeps landing on the weaker version.
That is the hidden cost of slow testing.
Traditional A/B testing is built to produce a clean comparison. You split traffic evenly, keep conditions stable, wait for enough data, and then declare a winner. If your priority is confidence and documentation, that process makes sense.
On a live revenue-driving page, the trade-off feels different. Every extra day on a fixed split means more visitors see an experience that may already be underperforming.
Where fixed-split testing starts to hurt
The pain usually shows up in practical marketing situations, not in theory:
- Short campaign windows: Promotions, launches, and peak trading periods can end before a standard test reaches a useful conclusion.
- Paid traffic pressure: If visits come from Google Ads, Meta, or affiliates, each impression sent to a weaker variant has a real acquisition cost attached to it.
- Fast tactical decisions: Sometimes the goal is simple. Pick the better hero image, CTA, or pricing message quickly and put more traffic behind it.
For teams using Otter A/B, that distinction matters. Some experiments are research projects. Others are operational decisions that need to improve performance while the test is still running.
Practical rule: If your goal is to maximise conversions during the experiment, not only after it ends, a bandit can be a better fit than a fixed-split test.
Classic A/B testing is good at answering a proof question: which version can we verify is better under controlled conditions? A multi armed bandit is better suited to an allocation question: where should the next visitor go if we want to keep learning without giving away unnecessary conversions?
What a multi armed bandit changes
A bandit still tests multiple variants. The difference is how traffic is distributed over time.
Instead of keeping every version on a fixed share, the system adjusts allocation as results come in. Early on, each option gets enough exposure to be judged fairly. As evidence builds, stronger variants receive more traffic and weaker ones receive less.
It works like a shop manager watching three window displays. At first, each display gets a similar chance. Once one starts drawing more people inside, the manager gives that display the front position instead of insisting on equal exposure for the other two.
That approach is often a better match for e-commerce and lead generation teams that care about two outcomes at once: learn which variant works best, and protect as much performance as possible while learning.
A more useful framing for marketers
Use fixed A/B tests when you need a careful answer you can defend.
Use a multi armed bandit when speed, efficiency, and in-flight performance matter more, especially on pages where Otter A/B customers want a clear implementation path rather than a long wait for statistical closure.
The Core Problem Exploration vs Exploitation
The phrase sounds academic, but the idea is simple. A multi armed bandit is trying to solve one decision problem over and over again:
Should I keep using the option that looks best so far, or should I keep testing other options in case one of them is better?
That tension is called exploration vs exploitation.
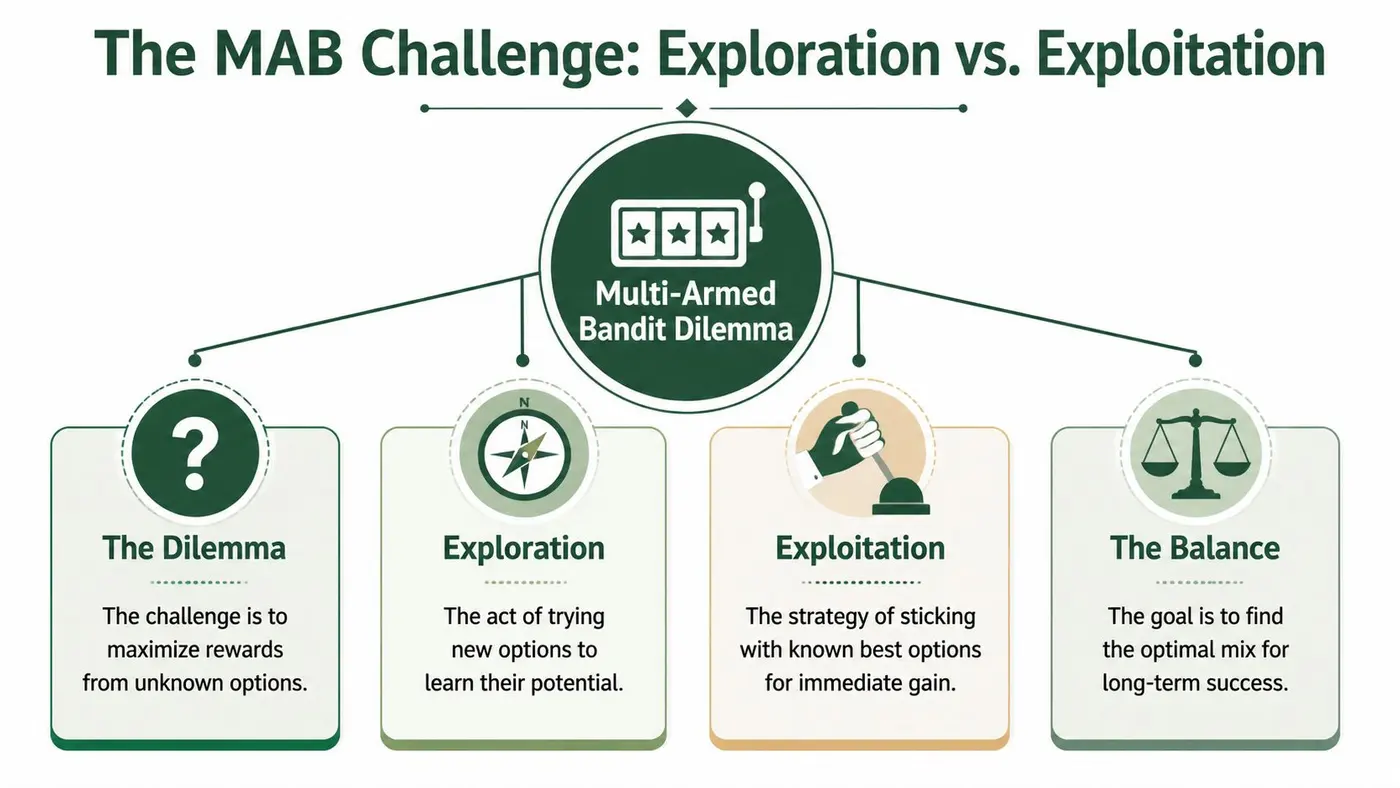
The casino analogy still works
Think about a row of slot machines. Each one has an unknown payout rate. You can pull any lever you want, but you only have limited time and limited budget.
You quickly hit a problem.
One machine seems promising. You could keep using it and collect steady returns. That’s exploitation.
But maybe another machine is even better, and you just haven’t tested it enough yet. Trying that machine is exploration.
What this looks like on a website
On a website, the slot machines are your variants:
- Headline A versus Headline B
- Green button versus black button
- Short checkout copy versus more reassurance-heavy copy
- Three hero images for the same product category page
Each visit gives you feedback. A click, purchase, or form completion acts like the “reward” from a slot machine.
The hard part is that you never know the true winner in advance. You only have partial evidence from the users you’ve already seen.
Too much exploration wastes traffic on mediocre options. Too much exploitation locks you into a premature winner.
That sentence captures the whole challenge.
Why marketers get stuck here
Many teams lean too hard in one direction.
Some explore for too long. They keep traffic spread evenly because they want cleaner evidence. That protects the analysis, but can hold back performance.
Others exploit too soon. They see an early leader, call it done, and scale the apparent winner before they’ve learned enough. That can backfire when early traffic was noisy or unrepresentative.
A good multi armed bandit sits between those extremes. It keeps learning, but it doesn’t ignore what it has already learned.
The key intuition
A bandit is not trying to produce perfect certainty at every moment. It’s trying to make the next traffic decision smarter than the last one.
That’s why it feels so different from classic experimentation. It isn’t a static test with a verdict at the end. It’s a stream of small allocation decisions, each informed by the latest results.
Once that clicks, the rest of the topic becomes much easier to understand.
Common Multi-Armed Bandit Algorithms Explained
The exploration problem is universal. The way you solve it depends on the algorithm.
You don’t need the maths to understand the practical difference. Each algorithm has its own personality. One is blunt and simple. One is cautious but optimistic. One is probabilistic and flexible.
Epsilon-Greedy
This is the easiest bandit strategy to grasp.
Most of the time, the algorithm sends traffic to the current best-performing variant. Occasionally, it ignores the leader and tries a random alternative. That random chance is the “epsilon” part.
Imagine a shop manager who usually puts the best-selling item in the front window, but every so often swaps in something else just to check whether customer taste has changed.
Why teams like it:
- It’s easy to explain to stakeholders.
- It’s simple to implement.
- It keeps exploration alive instead of shutting it off completely.
Where it can feel clumsy:
- Exploration can be too random.
- It doesn’t always adapt elegantly as uncertainty changes.
Upper Confidence Bound
Upper Confidence Bound, often shortened to UCB, is more deliberate.
Instead of just asking, “Which variant looks best right now?”, it asks, “Which variant could plausibly be the best once I account for uncertainty?” A version with little data may get extra traffic because the system hasn’t learned enough about it yet.
A useful analogy is hiring. One candidate has a solid record and lots of references. Another has fewer references but unusually strong signals. UCB gives weight to both current performance and how much uncertainty remains.
That makes it a good fit when you want a principled way to avoid ignoring under-tested options.
Thompson Sampling
Thompson Sampling is the bandit method many practitioners find elegant because it behaves in a very natural way. It treats each variant as a probability question and repeatedly asks which option is most likely to be the best.
You can think of it as running lots of tiny “what if” scenarios in the background, then picking the variant that most often comes out ahead.
This often makes Thompson Sampling feel smooth in production. It explores when uncertainty is high and leans harder into winners as confidence grows.
If you want a clearer grounding in the statistical mindset behind this, Otter A/B’s guide on Bayesian and frequentist testing is a useful companion.
Working heuristic: Epsilon-Greedy is simple, UCB is structured, Thompson Sampling is adaptive.
Which one should you care about most
For a marketing team, the key question usually isn’t the formula. It’s operational fit.
- If you want the simplest mental model, Epsilon-Greedy is easiest.
- If under-explored variants are a recurring concern, UCB is attractive.
- If you want a flexible method that balances learning and optimisation gracefully, Thompson Sampling is often the one people reach for.
The algorithm matters. The use case matters more.
Multi-Armed Bandit vs A/B Testing A Strategic Comparison
A marketing team launches a new homepage promo on Monday. By Tuesday afternoon, one headline is already pulling ahead. The practical question is simple: do you keep splitting traffic evenly so you can get a clean verdict later, or do you start sending more visitors to the stronger option now?
That is the choice between these methods.
The strategic difference
A classic A/B test is built for measurement. You hold the traffic split steady, protect the comparison, and wait for a result you can explain clearly to stakeholders. If your team is changing a pricing page, testing a new onboarding flow, or validating a bigger UX decision, that structure is often exactly what you want.
A multi-armed bandit is built for adaptation. It keeps learning, but it also keeps adjusting traffic while the experiment is live. That makes it a strong fit for decisions where delay has a direct cost, such as promo banners, CTA copy, hero images, headline rotations, and short-lived campaign pages.
Another way to frame it is this: A/B testing answers, “Which version won?” A bandit answers, “How can we keep learning while wasting less traffic on weaker options?”
For a grounding in the basics of classic experimentation, this explainer on what an A/B test is helps frame the contrast.
MAB vs A/B Testing Which to Choose?
| Criterion | A/B Testing (Frequentist) | Multi-Armed Bandit |
|---|---|---|
| Traffic allocation | Fixed for the duration of the test | Adjusts as results come in |
| Main goal | Learn which version wins with a clean comparison | Maximise reward while learning |
| Cost of weak variants | Can stay high until the test ends | Usually reduced over time |
| Best use case | Strategic decisions and bigger UX questions | Tactical optimisation and live campaigns |
| Interpretation | Often easier for broad stakeholder groups | Can feel less intuitive at first |
| Timing | Better when you can wait for a full readout | Better when speed to value matters |
Where the tradeoff shows up in practice
The simplest way to understand the difference is to follow the visitor flow.
With A/B testing, Variant B can look weak early on, but it still keeps getting its assigned share of traffic because the test is protecting the integrity of the comparison. That is useful when your main goal is confidence in the final answer.
With a bandit, the system starts reducing exposure to weaker options as evidence builds. You still learn, but you also protect more visitors from poor experiences during the test. For a revenue-minded team, that is often the strongest business case for using a bandit.
This matters most on pages where small choices repeat at scale. A homepage hero, paid landing page headline, or promotional offer can affect thousands of sessions before a fixed-split test finishes. If your team is already mapping these moments across touchpoints, Formbricks has a useful guide on how to optimize customer journeys.
A short walkthrough helps if you want to see this contrast explained visually:
When not to use a bandit
Bandits are not the default answer.
If success takes weeks to show up, such as a long sales cycle, delayed revenue event, or downstream lead-quality metric, adaptive allocation gets harder to manage well. The feedback arrives too slowly, so the system has less to react to in real time.
They are also a weaker fit when your team needs a plain, defensible readout for executives, clients, or regulated review. A fixed-split A/B test usually gives a cleaner story.
For Otter A/B customers, the practical takeaway is straightforward. Use a bandit when the page element is narrow, the reward signal is fast, and capturing upside during the test matters. Use A/B testing when the priority is a stable comparison and a result your team can present without much interpretation.
Putting Theory into Practice Implementing MAB on Your Website
A bandit works best when the test is narrow, the reward signal is fast, and the team knows exactly what decision it wants the system to make.
That means the implementation starts before you pick an algorithm. It starts with experiment design.
Start with the right candidate
Good bandit candidates tend to share three traits:
- One focused element: headline, CTA, banner, hero image, offer framing.
- A fast reward signal: clicks, add-to-basket actions, purchases, or form submissions.
- A meaningful reason to adapt traffic quickly: live campaigns, paid landing pages, homepage promos.
Poor candidates are usually broad redesigns with lots of moving parts. If three things change at once, the bandit may still optimise, but your team won’t learn much about why the winner won.
Define the reward cleanly
A multi armed bandit can only optimise the thing you tell it to optimise.
If your main objective is revenue, don’t optimise for clicks unless clicks are a reliable stand-in. If your objective is lead quality, don’t treat all form completions as equal if they clearly aren’t.
That’s where many programmes go sideways. The algorithm behaves correctly, but it’s chasing the wrong reward.
For teams mapping these moments across pages and touchpoints, Formbricks has a practical guide on how to optimize customer journeys. It’s a useful way to think beyond a single page and connect experiments to a fuller user path.
Expect some operational friction
Bandits are often sold as automatic. They are adaptive, but they’re not maintenance-free.
A 2025 UK case study discussed by Lilian Weng reported that 40% of digital agencies that tried MAB temporarily paused their programmes because of unexpected documentation and audit overhead.
That’s a real warning sign, especially for agencies and larger in-house teams. The harder the system is to explain, the more important it becomes to document:
- Why this test used MAB rather than fixed-split A/B
- What event counted as the reward
- How traffic allocation changed over time
- What rule determined when to stop or scale
A bandit should reduce wasted traffic, not create a reporting mess.
Keep the setup observable
Your engineering and analytics teams need a clean implementation path. That includes event tracking, variant assignment, and a way to inspect what happened when results are questioned later.
If you’re wiring custom events or integrating your own front-end logic, clear implementation references matter. The Otter A/B API documentation is a good example of the kind of technical reference teams should have available when building or reviewing experiment workflows.
The practical takeaway is simple. A bandit isn’t just an algorithm choice. It’s an operating model. The teams that get value from it stay disciplined about scope, reward definition, and documentation.
A Recommended MAB Workflow for Otter A/B Users
A multi armed bandit becomes much easier to use when the workflow is concrete. The goal is not to think like a statistician all day. The goal is to make better traffic allocation decisions with less manual effort.
Step 1 Pick one high-impact element
Start with a test that has a fast feedback loop. A homepage headline, product page CTA, pricing page reassurance block, or lead form button is ideal.
Don’t start with a full-page redesign. You want a clean signal and a narrow decision.
Step 2 Add variants that reflect real hypotheses
Create a control and a few challengers. Make the differences meaningful enough to matter, but not so broad that you’re testing several ideas at once.
A useful pattern is to vary one thing thoroughly rather than five things shallowly. If you’re testing a CTA, focus on message angle, not colour, layout, icon, and surrounding copy all at once.
Step 3 Choose a primary goal
Tell the system what success looks like. That might be button clicks, form submissions, purchases, or a custom revenue event.
Be strict here. One primary goal keeps decision-making clear. Secondary metrics are still useful for review, but the bandit needs one reward signal to optimise against.
Step 4 Launch and watch allocation shift
Once live, the bandit begins by learning across variants. As the pattern sharpens, traffic moves toward the stronger options.
This is the moment many teams find compelling. You’re not waiting passively for the experiment to end. The allocation adapts while the campaign is still active.
Step 5 Read the results operationally
Look at two things together:
- Performance direction: which variant is attracting more traffic and still holding up on the chosen goal
- Business fit: whether the winner also makes sense for brand, UX, and downstream metrics
A bandit can identify a strong performer. Your team still decides whether it should become the default experience.
Step 6 Build a repeatable cadence
Optimal results come from rhythm. Teams usually get the most value when they reserve bandits for tactical, high-traffic opportunities and keep classic A/B tests for broader product questions.
The smartest experimentation programmes don’t choose one method forever. They match the method to the decision.
That mindset keeps the tool practical. You use a multi armed bandit where speed and regret reduction matter most, and you don’t force it into jobs it was never meant to do.
Experiment Smarter Not Harder
A multi armed bandit helps teams stop treating optimisation like a waiting game. Instead of holding traffic in a rigid split until a test finishes, you let the system learn and adapt while real visitors are still arriving.
That’s why bandits fit tactical CRO work so well. They’re strong when you’re testing high-visibility elements, working with fast feedback loops, and trying to protect conversions during the experiment itself.
They are not a replacement for every A/B test. Large product changes, slower metrics, and high-scrutiny decisions still benefit from classic fixed-split testing. The key skill is choosing the right method for the job.
If you enjoy practical experimentation thinking beyond this topic, browsing IllumiChat's latest articles can spark useful ideas on how teams turn technical tools into better customer experiences.
The core takeaway is simple. If your current tests feel too slow for the decisions you need to make, a multi armed bandit is worth serious attention.
If you want to put these ideas into practice, Otter A/B gives your team a lightweight way to run experiments on headlines, CTAs, layouts, and revenue-focused goals without adding friction to the site experience. It’s built for fast-loading website tests, clear reporting, and quick setup across platforms like Shopify, WordPress, Webflow, WooCommerce, and Next.js, so you can move from theory to live optimisation quickly.
Stop guessing
Ready to start testing?
Set up your first A/B test in under five minutes. No credit card required.
- 14-day free trial
- No credit card required
- Cancel anytime