Mastering One Tailed Vs Two Tailed A/B Tests
Master one tailed vs two tailed tests for A/B testing. Get clear examples and learn when to use each to boost your data-driven decisions.

You’ve likely had this result on your screen before. Variant B is up. The graph looks encouraging. Stakeholders are already asking whether they can ship it. Then you look at significance and the result sits just outside the line you needed.
That’s where the one tailed vs two tailed decision stops being a statistics lecture and becomes an operating choice. It affects how fast you can call winners, what kinds of losses you can catch, and whether your testing process protects revenue or leaves it vulnerable.
For teams running experiments inside platforms that calculate significance continuously, this choice matters even more. Speed is useful. False confidence is expensive.
The 4.9% Uplift Dilemma
A common testing story goes like this. You launch a homepage headline test on Monday. By the end of the second week, variant B is showing a 4.9% uplift. The team likes the new version. Sales thinks the message is stronger. Design prefers it. The result feels close enough to call.
Then the analytics conversation starts.
Someone asks whether the result would have passed if you’d used a one-tailed test instead of a two-tailed one. Another person asks why the platform didn’t mark it significant. A third asks the dangerous question: can’t we just analyse it that way now, since our hypothesis was always that the new headline would improve conversions?

That situation is frustrating because the result looks commercially promising. It also exposes a habit that causes weak experimentation programmes. Teams treat one tailed vs two tailed as a reporting preference, when it is part of the test design.
Why this scenario keeps happening
Understanding the distinction between a control and a variant isn't typically the issue. The struggle often lies with the consequences of choosing the wrong statistical frame before launch.
A one-tailed test asks a narrower question. A two-tailed test asks a broader one. If you set the wrong question at the start, the ending gets messy fast.
The biggest mistake isn’t choosing the “wrong” tail. It’s choosing the tail after seeing the result.
The business pressure behind the stats
Indeed, a near-miss result creates real pressure:
- Product wants speed because delays slow down rollout.
- Marketing wants a win because campaigns and messaging plans depend on it.
- Merchandising wants protection because a weak decision can hurt conversion quality, basket value, or user trust.
- Analysts want consistency because once teams start changing the rules after the fact, no result is trustworthy.
That’s why this isn’t an academic footnote. The one tailed vs two tailed choice determines whether you’re optimising for faster detection or broader protection.
Defining One-Tailed and Two-Tailed Tests
The simplest way to understand one tailed vs two tailed testing is to focus on the question each test is allowed to answer.
A one-tailed test checks for an effect in one specified direction only. In an A/B test, that usually means asking whether variant B is better than control. Not different. Better.
A two-tailed test checks for a difference in either direction. It asks whether variant B is different from control, whether that difference is positive or negative.
| Test type | What it asks | What it can detect | Best fit |
|---|---|---|---|
| One-tailed | Is B better than A? | Effects in the predicted direction only | Narrow, strongly justified directional hypotheses |
| Two-tailed | Is B different from A? | Positive or negative effects | Most product, UX, and revenue-sensitive tests |

A practical mental model
Visualize it as searching a room.
If you believe the keys are in the left corner and only care about finding them there, you search that corner hard. That’s one-tailed testing.
If you need to know whether the keys are anywhere in the room, you search both sides. That’s two-tailed testing.
The first approach is more focused. The second is more cautious.
How that maps to A/B testing
Here’s what the hypotheses often look like in practice:
-
One-tailed hypothesis
- Null hypothesis: Variant B does not improve the metric versus A.
- Alternative hypothesis: Variant B improves the metric versus A.
-
Two-tailed hypothesis
- Null hypothesis: Variant B does not differ from A.
- Alternative hypothesis: Variant B differs from A.
This distinction sounds small, but it changes the way significance is evaluated and how much surprise your test design is willing to tolerate.
If your team needs a refresher on how uncertainty is represented around test estimates, this guide to confidence intervals in statistics is useful background reading.
Where marketers usually get confused
The confusion usually comes from intent. Teams often say, “We only launched this because we thought it would win.” That’s not enough to justify a one-tailed test.
Every experiment is launched because someone expects improvement. That expectation alone doesn’t remove the possibility of harm. A new headline can reduce clarity. A redesigned CTA can distract from the primary action. A checkout tweak can increase friction even if the design team expected the opposite.
If a downside outcome would change your decision, then the downside matters statistically too.
That’s why two-tailed testing is the default professional standard in many experimentation contexts. It reflects that user behaviour doesn’t always follow the story told in the kickoff meeting.
Statistical Trade-Offs Power Errors and Sample Size
The reason teams debate one tailed vs two tailed isn’t terminology. It’s the trade-off between speed and protection.
A one-tailed test is more efficient when your directional assumption is correct. According to Statistics Solutions on one-tailed and two-tailed test selection, one-tailed tests concentrate 100% of statistical power in a single direction, making them approximately 1.96x more sensitive than two-tailed tests at detecting effects in the hypothesised direction. In practical A/B testing terms, that means a one-tailed test can detect a true lift with the same sample size that would require roughly double the visitors in a two-tailed test. The same source also notes the cost of that focus: if the treatment performs worse in the opposite direction, the one-tailed test will miss that effect entirely.
Why more power feels attractive
That extra sensitivity is seductive for good reason. If you run tests on smaller traffic segments, niche landing pages, or regional campaigns, waiting longer for certainty can block your roadmap.
A one-tailed test can help when all of the following are true:
- The hypothesis is directional and grounded in prior evidence, not optimism.
- The opposite outcome isn’t decision-relevant because you have safeguards elsewhere.
- You need faster reads on low-volume experiments.
- The implementation risk is narrow and unlikely to create broad UX damage.
For teams that live under traffic constraints, this can turn a test from impractical to usable.
What you give up
The hidden cost is asymmetry. A one-tailed test doesn’t just become less interested in the opposite direction. It becomes structurally unable to flag it the same way.
That matters when you’re testing something with potential side effects. A CTA might increase clicks but attract lower-intent visitors. A layout change might help one segment and hurt another. A checkout experiment might appear neutral on the top-line conversion metric while creating damage elsewhere in the funnel.
If you need a clean refresher on false positives and missed effects, this explainer on Type I vs Type II errors is worth keeping handy.
The sample size reality
A two-tailed test asks more from your data because it has to remain open to both upside and downside. That’s why it usually takes longer to reach significance.
That extra time isn’t waste. It’s what you pay for broader detection.
Practical rule: Shorter tests aren’t automatically better tests. Faster significance only helps if the test design still matches the business risk.
This is a good point to slow down and watch the mechanics in action:
How this lands in the real world
For a low-stakes headline test, using a one-tailed test might be completely defensible if you’ve already validated the messaging direction in prior work.
For a major navigation change, pricing page restructure, or checkout redesign, that same choice can create blind spots you don’t want. The broader the possible consequences, the more value there is in a method that can catch the result you weren’t expecting.
In this regard, good CRO teams separate themselves from hurried ones. They don’t ask only, “How can we detect a win faster?” They also ask, “What kind of loss would this test fail to reveal?”
Practical A/B Testing Examples in Action
Theory gets clearer when you attach it to the kinds of experiments teams run.
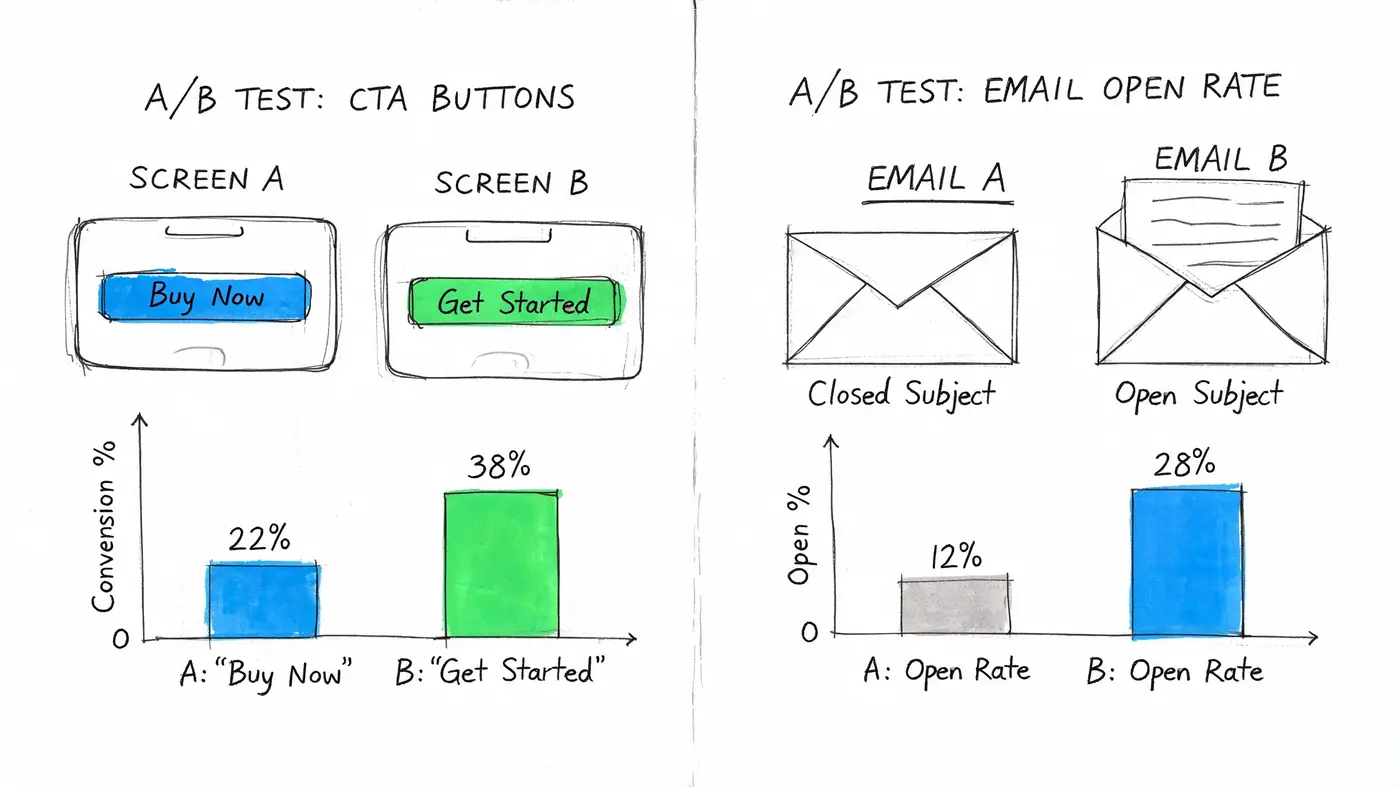
Example one: CTA test on a landing page
Say you’re testing a new CTA on a Webflow landing page. The current button says “Start Free Trial”. The variant says “See It In Action”. You believe the new wording will reduce commitment anxiety and increase clicks into the signup flow.
That sounds directional. But should the analysis be one-tailed?
Write the hypotheses first.
-
One-tailed version
- Null: The new CTA does not improve conversion to signup.
- Alternative: The new CTA improves conversion to signup.
-
Two-tailed version
- Null: The new CTA does not change conversion to signup.
- Alternative: The new CTA changes conversion to signup.
The practical question isn’t whether the team expects improvement. Of course it does. The key question is whether a drop in click-through or signup quality would matter enough to stop rollout.
On landing pages, that downside usually does matter. Small wording changes can alter user intent, lead quality, and page flow. If you’re looking for inspiration before testing, these effective strategies for landing pages are a useful input for stronger hypotheses and better page structure.
For prioritisation, the better move is often to decide the test candidate first, then decide the tail choice. A clear framework for deciding what to A/B test helps stop teams from forcing directional certainty onto weak ideas.
Example two: recommendation logic on a Shopify store
Now switch to a Shopify product page. You’re testing a new recommendation module below the add-to-cart section. The goal is to lift average order value.
The choice between one-tailed and two-tailed tests requires more careful consideration. You might believe the new recommendations will increase basket size. But recommendation logic can also distract from the primary purchase, reduce focus, or push irrelevant products that lower trust.
So the hypotheses could be written like this:
-
One-tailed approach You’re only testing whether the new module increases AOV.
-
Two-tailed approach You’re testing whether the module changes AOV in any direction, including harm.
In a worked z-test, the mechanics differ because the decision boundary differs. The raw underlying result could look promising in both setups, yet only the one-tailed version clears the threshold if the observed change is modest and aligned with the predicted direction.
That’s exactly why the method choice has to be locked before launch. Otherwise you’re not just analysing the result. You’re selecting the rule that gives you the answer you wanted.
A directional hypothesis is credible when it was defensible before exposure started, not when it becomes convenient after the dashboard updates.
What these examples show
Neither example has a universal “correct” answer. The right choice depends on business context.
A narrow copy test with limited downside can justify a one-tailed approach. A recommendation engine that touches revenue quality and user trust usually deserves a two-tailed one.
The method should follow the risk profile of the change, not the enthusiasm of the team proposing it.
How to Choose The Right Test for Your Experiment
A default rule is generally needed. Mine is simple. If the change can plausibly help or hurt the experience in a way that would affect rollout, use a two-tailed test.
That bias towards caution exists for a reason. According to FigPii’s explanation of one-tailed versus two-tailed tests, at a 95% confidence level, a two-tailed test splits α = 0.05 across both ends of the distribution, allocating 0.025 to each tail, while a one-tailed test commits the full 0.05 to one direction. The same source notes that this stricter setup reduces Type I error risk by making it harder to declare significance too early.
Use this decision filter
Ask these questions before the test goes live.
-
Would an unexpected negative effect change the rollout decision?
If yes, two-tailed is the safer choice. -
Is the hypothesis supported by more than preference or intuition?
If the answer is no, don’t use a one-tailed test to compensate for weak evidence. -
Is the experiment touching a critical journey?
Checkout, onboarding, pricing, navigation, and high-intent product pages usually justify broader detection. -
Is the change low-risk and tightly scoped?
That’s where a one-tailed test can be reasonable if the directional case is already strong.
Where two-tailed should usually win
I’d use two-tailed as the default for:
| Experiment type | Recommended default | Why |
|---|---|---|
| Checkout flow changes | Two-tailed | Unexpected friction is expensive |
| Navigation or layout shifts | Two-tailed | Behaviour can change in several ways |
| Pricing or offer presentation | Two-tailed | Negative reactions matter as much as lifts |
| Broad homepage redesigns | Two-tailed | Multiple metrics can move unexpectedly |
Where one-tailed can be justified
A one-tailed test can be sensible when the intervention is narrow and the downside is limited. Think small CTA wording changes, modest merchandising tweaks in a contained segment, or follow-up tests where prior rounds already established a credible direction.
That still requires discipline. Your team should be able to explain why the opposite direction is not the core decision question.
If you’re evaluating tooling and workflow maturity more broadly, Trackingplan's AB platform insights offer a useful lens on what teams should look for in experimentation platforms beyond surface-level reporting.
Conservative testing doesn’t slow growth. It stops teams from scaling noise.
A practical policy that works
For many organisations, the cleanest policy is:
- Default to two-tailed
- Allow one-tailed only with written pre-test justification
- Document the primary metric and stopping rule before launch
- Treat post-hoc tail switching as invalid analysis
That policy keeps debate where it belongs. Before exposure, not after.
Common Pitfalls and Advanced Considerations
Most articles on one tailed vs two tailed stop too early. They explain directional hypotheses, mention sample size, and move on. That leaves out the part that causes the most confusion in actual testing workflows: continuous monitoring.
When teams can check significance whenever they want, the clean theoretical advantage of one-tailed testing gets messier. According to Jim Frost’s discussion of one-tailed and two-tailed hypothesis tests, the statistical power trade-off in continuous monitoring scenarios is underexplored. The same discussion notes that while one-tailed tests have more power, that advantage can erode when sequential testing and continuous monitoring increase Type I error rates, especially when practitioners also risk missing opposite-direction effects.
Peeking changes the practical risk
In many platforms, people don’t wait until the end. They check results daily. Sometimes hourly. They pause weak tests early and celebrate strong-looking ones early.
That behaviour changes the practical meaning of significance.
A one-tailed framework might look attractive because it appears to get to an answer faster. But if the team is also peeking constantly and making informal stop decisions, some of that speed advantage gets diluted by a noisier decision process.
The post-hoc switch is invalid
The most common abuse is this one: launch with a two-tailed setup, miss significance narrowly, then reframe the result as one-tailed because the original business hypothesis was positive.
That is not a methodological refinement. It is rule-changing after the outcome is visible.
Here’s the standard worth defending:
- Set the tail choice before launch
- Keep it fixed throughout the experiment
- Don’t rewrite the hypothesis after looking at the chart
- Document why the chosen tail fits the business risk
If the analysis plan changes because the result is inconvenient, confidence in the result should drop immediately.
Continuous monitoring needs extra discipline
The practical fix isn’t to avoid looking at your dashboard. Teams will look. The fix is to create guardrails around what those looks can trigger.
Use a written stopping rule. Decide who can call a test. Make sure secondary metrics are reviewed before rollout. If you’re testing revenue-critical flows, ask whether your chosen method can detect the kind of failure you most need to avoid.
That last question matters more than teams admit. In ecommerce, the most dangerous tests are rarely the obvious losers. They’re the tests that look fine on the primary metric while introducing subtler damage elsewhere.
Frequently Asked Questions
Why is a two-tailed test the default in most A/B testing tools?
Because it fits the reality of most product and marketing experiments. Teams usually need to know whether a variant changed performance in either direction, not just whether it improved. That makes two-tailed testing the safer default when downside outcomes would affect rollout.
When is a one-tailed test actually the better business choice?
When the hypothesis is strongly directional, the scope is narrow, and the downside risk is limited enough that the opposite-direction effect is not the main decision concern. That can apply to tightly scoped tests such as refined messaging or minor interface adjustments, especially where traffic is limited and speed matters.
Can I switch from a two-tailed analysis to a one-tailed analysis after the experiment ends?
No. If you do that because the result was close, you’ve changed the decision rule after seeing the data. That weakens the credibility of the conclusion. Choose the test type before launch and keep it fixed.
Does one-tailed always mean better for faster experimentation?
Not automatically. It can improve sensitivity in the predicted direction, but the practical advantage can shrink when teams monitor results continuously and make informal stop decisions. Faster isn’t helpful if the process also increases the chance of false confidence or masks a harmful outcome.
What’s the simplest operating rule for most teams?
Use two-tailed by default. Only use one-tailed when you can defend it in writing before the test starts.
If your team wants a cleaner way to run experiments without slowing down the site, Otter A/B gives you a lightweight testing setup, continuous significance tracking, and reporting tied to real business outcomes like purchases, average order value, and revenue. It’s a practical fit for marketers, product teams, and ecommerce operators who want faster experimentation without making the analysis sloppy.
Stop guessing
Ready to start testing?
Set up your first A/B test in under five minutes. No credit card required.
- 14-day free trial
- No credit card required
- Cancel anytime