What Is a Control Group: Reliable A/B Tests
Understand what is a control group and its vital role in valid experiments. Use controls in A/B testing to get results you can trust in 2026.

A control group is the unchanged group in an experiment, and it gives you the baseline that shows whether your test changed anything at all. In most randomised experiments, a 50/50 split between treatment and control gives you the strongest statistical power, while pushing the control share below 30% can drag a study under the common 80% power benchmark.
You're probably here because you've run, or want to run, an A/B test and need a straight answer to one deceptively simple question: what is a control group?
In CRO, this isn't classroom vocabulary. It's the thing that stops you from shipping a homepage, checkout, or CTA change because “conversions looked up this week” when the lift came from paid traffic, seasonality, or a lucky mention in a newsletter. If you get the baseline wrong, the whole readout becomes shaky.
The control group is what keeps you honest. It's the original version of the page, shown to a portion of users while another portion sees the changed version. That side-by-side comparison is what turns a guess into an experiment.
Your North Star in the Fog of Data
A team launches a new homepage headline on Monday. By Friday, sign-ups look stronger. Slack gets noisy. Someone wants to push the new headline live for everyone before the weekend.
Then the awkward question lands. Did the headline work, or did a well-timed traffic spike make the numbers look better than they really are?
That's the everyday problem a control group solves. Without one, you're comparing this week with last week and hoping nothing else changed. On a live site, something else is almost always changing. Traffic sources shift. Buyers behave differently by day. Promotions end. Competitors move. Your own campaigns send a different mix of visitors.
Why before-and-after comparisons mislead
A before-and-after read can feel persuasive because it tells a clean story. You changed a button, conversions rose, so the button must have worked. But business data is messy. Many forces move at the same time, and some of them are invisible unless you're actively looking for them.
That's why good experimentation needs a fixed point. The control group is that fixed point. It's the unchanged experience that runs at the same time as your variant, against the same market conditions, so you can compare like with like.
When you remove the baseline, you don't remove uncertainty. You just hide it.
For marketers, a useful mental model is a compass. Teams often talk about a north star metric for growth, but a metric only helps if you trust the way it's measured. The control group is what makes movement in that metric interpretable during a test.
What the control looks like on a website
In a website experiment, the control is usually Version A. It might be your current product page, your existing checkout flow, or the original hero section on your landing page. The variant changes one thing you want to test, such as:
- A new headline that promises a different value proposition
- A redesigned CTA with new wording or placement
- A shorter form that removes fields
- A revised layout that changes information order
If the control converts better, that matters. If the variant wins, that also matters. Either way, the control gives you the benchmark. Without it, you're navigating fog with no landmark and making expensive calls from incomplete evidence.
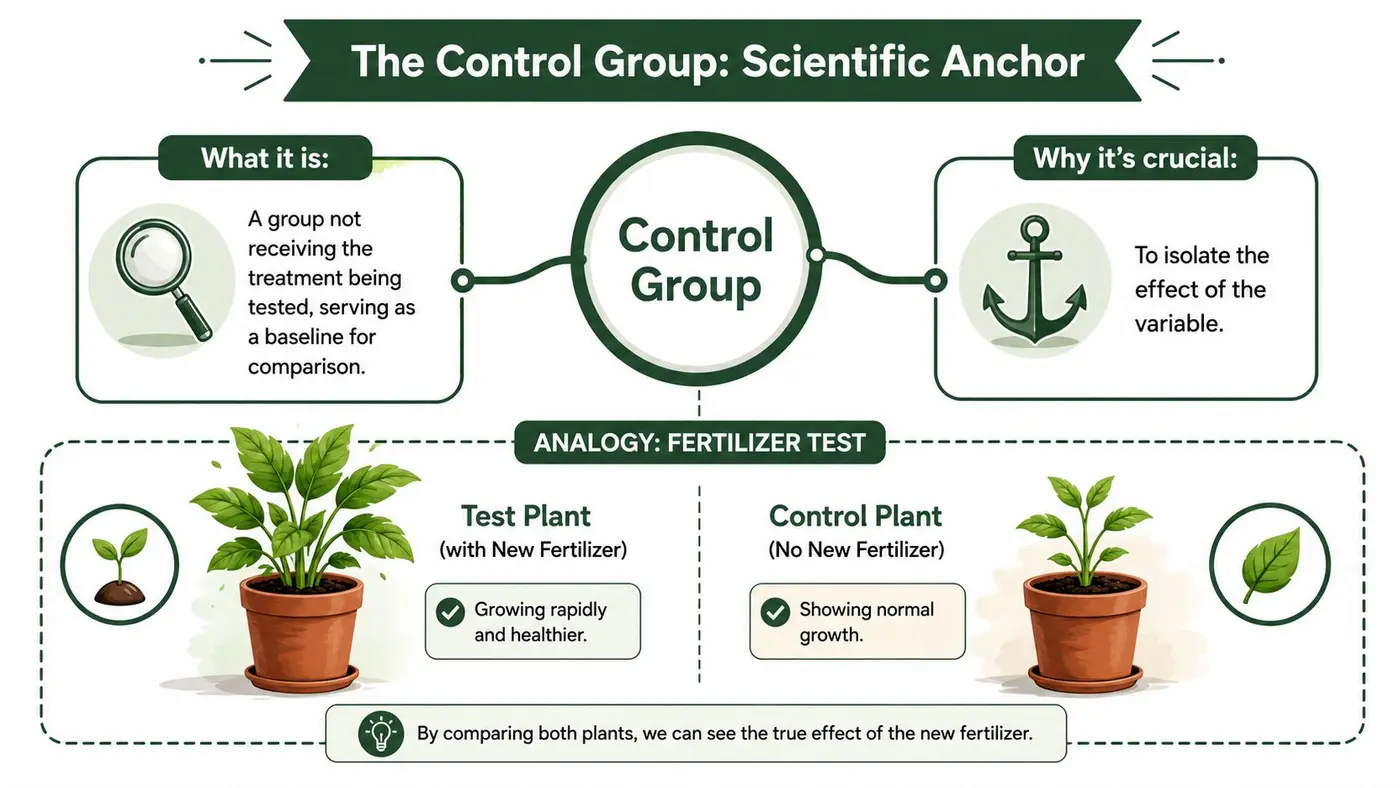
The Control Group Explained The Scientific Anchor
A control group is the baseline comparison in an experiment. It gets no treatment, a placebo, or standard care so researchers can isolate the effect of the intervention. The idea is so central to research that many scholars reserve the word experiment for studies that include a control group, as explained in this overview of control groups.
That sounds academic, but the logic is simple.
The fertiliser and running-shoes way to think about it
Take two similar plants. Give one a new fertiliser. Give the other the same water, the same light, and no fertiliser. If the treated plant grows differently, you have a meaningful comparison. The untreated plant is the control group.
The same idea works with a race analogy. Two runners train under the same conditions. One runner gets new shoes. The other keeps the old pair. If the runner with new shoes performs differently, you can start to ask whether the shoes played a role. If both runners changed shoes, or both switched training plans at the same time, you'd lose the comparison.
Website tests work exactly like that.
- Control group: people see the current version of the page
- Treatment group: people see the changed version
- Goal: measure whether the change caused a different outcome
Memorable definition: A control group is the unchanged version that tells you what would have happened if you had done nothing new.
Here's a short walkthrough if you want the concept explained visually before you apply it to CRO:
Why the baseline matters so much
People often hear “baseline” and think it's just an administrative detail. It isn't. The baseline is the whole point. You're not really asking whether conversions are high or low in isolation. You're asking whether the changed version performed differently from the unchanged version under comparable conditions.
That's what makes the result actionable.
If your original pricing page converts at one level and the new pricing page converts at another, the difference between those two groups is what matters. Without the control, you're left with a raw outcome and no proper benchmark.
Why Your A/B Tests Need a Control Group
A proper A/B test needs a counterfactual. In plain English, that means you need an estimate of what would have happened if you hadn't changed anything. In control-group designs, the untreated arm acts as that counterfactual baseline, which helps reduce confounding from things like seasonality or traffic mix that can create the illusion of an effect, as outlined by BetterEvaluation's explanation of control groups.
That sentence sounds technical, so let's put it in marketer terms. The control group answers the question, “What would this page have done anyway?”
The noise your test is fighting
Suppose you test a new product page layout during a holiday period. Orders rise. That doesn't automatically mean the layout worked. The holiday itself may have raised buyer intent. Or your paid team may have launched a campaign that brought in warmer traffic.
Without a control group running in parallel, you can't separate the effect of your page change from the effect of everything else happening around it.
Here are the usual suspects:
- Seasonality: buyer behaviour changes around holidays, launches, and pay cycles
- Traffic mix: branded search, email, affiliates, and paid social bring different intent levels
- Competitor activity: another brand's sale can push demand toward or away from you
- Site changes elsewhere: shipping messaging, stock levels, and pricing can shift performance
The business cost of getting this wrong
False positives are expensive. If you roll out a losing variant because it looked good in noisy data, you don't just lose conversion rate. You waste design time, development time, and stakeholder trust.
That's why performance teams treat control groups as operating discipline, not statistical decoration. If you're building a wider testing programme across channels, this practical guide for performance marketers is useful because the same logic applies in ad creative testing too. You need a clean baseline before you can trust any read on uplift.
The control group doesn't make your experiment perfect. It makes your interpretation far less fragile.
What confidence actually means in practice
For a junior marketer, the leap is usually this: “results changed” is not the same as “our change caused the result.”
A control group helps you make that second statement with much more confidence. It doesn't eliminate every risk. But it removes the biggest analytical trap in CRO, which is mistaking coincidence for causation.
That's the “so what” behind the term. A control group protects decisions. It helps you avoid redesigning a checkout because of noise, rewriting a value proposition because of a traffic blip, or killing a good idea because the comparison was flawed from the start.
Different Types of Control Groups and When to Use Them
In website testing, the control often means “show the current page to some users.” That's the standard setup. But not every experiment can use a pure do-nothing comparison.
Clinical research makes this easier to see. When withholding an effective treatment would be unethical, researchers may use an active control and compare the new option with the current standard treatment instead of a placebo, as described in the National Cancer Institute definition of control group.
The same logic shows up in digital work. Sometimes your “control” isn't a blank baseline. It's the current best version you already trust.
Control Group Setups at a Glance
| Control Type | Description | Best Used When |
|---|---|---|
| No-treatment control | Users get the existing version with no new change applied | Standard A/B tests on landing pages, checkout steps, or CTA copy |
| Active control | Users get the current best-performing or standard version, while another group sees a new challenger | You already have a strong incumbent design and need to beat it fairly |
| Historical control | You compare current results against past performance rather than a live parallel group | A live split test isn't possible, though this is weaker than concurrent testing |
| Standard-care control | Participants receive the normal experience or usual service rather than nothing | Product or service environments where removing the current experience would be impractical |
How to choose the right control
The right question isn't “What is the purest textbook version?” It's “What baseline gives us the fairest comparison?”
For most CRO work, that means keeping the current experience live as the control. If your product team has already rolled out a carefully optimised onboarding flow, your next experiment should usually test against that flow, not against some stripped-back version no real user would ever see.
A few practical rules help:
- Use a no-treatment control when the current page is stable and you want to isolate one new idea.
- Use an active control when you're comparing a challenger against an established winner.
- Use a historical control cautiously when operational limits block a proper split test. Treat conclusions as directional, not definitive.
- Use standard care as the baseline when users already depend on an existing experience and removing it would distort the test.
Not every control group is “nothing happens here”. Often it means “this group gets the current normal experience”.
That distinction matters because it clears up a common misconception. A control group is not always passive. It is the benchmark against which the treatment is judged.
Setting Up Your Control Group for Statistical Integrity
A control group only works if the setup is clean. If assignment is sloppy, if the sample is lopsided, or if the control keeps changing mid-test, the label “control” won't save you.

Randomisation comes first
Random assignment is what makes the groups comparable on average. Instead of sending mobile users into one group and desktop users into another, or routing traffic manually, you let the experiment platform assign users impartially.
That matters because it reduces selection bias. If one group gets systematically different visitors, your result may reflect audience differences rather than page differences.
This principle also matters before the experiment begins. If you're screening participants for research, or defining inclusion criteria for a study, the screening process itself shapes the quality of the comparison. That's why this app store research's guide on screeners is worth reading. Good screening and good randomisation solve different problems, but both protect validity.
Allocation is not an afterthought
Control size affects whether your experiment can detect a real effect. Research on randomised experiments shows that a 50/50 split between treatment and control generally maximises statistical power, and shrinking the control below 30% can push a study below the commonly accepted 80% power threshold, as explained in this discussion of control group size and power.
That has a direct CRO implication. Teams sometimes try to “save traffic” by giving the control a small share and pushing most users into the variant. The instinct is understandable. The consequence is often a weaker test.
Four rules that keep the baseline trustworthy
- Assign users randomly: every eligible visitor should have an equal chance of landing in control or variant.
- Keep the control stable: don't edit copy, layouts, tracking, or offer details halfway through.
- Vary one independent variable: if you change headline, CTA, and page structure all at once, you won't know what caused the result.
- Plan sample needs before launch: use a sample size calculator for A/B tests instead of guessing when “enough data” has arrived.
Practical rule: If you want to trust the winner, make sure the control experience stays unchanged while the variant changes only the thing you're testing.
Tools should support the methodology
This is also where tooling matters. Platforms such as Google Optimize alternatives, VWO, Optimizely, and Otter A/B can handle traffic splits and test setup. What matters is not the brand name. It's whether the tool lets you preserve a stable control, randomise allocation properly, and read outcomes against the right baseline.
If those mechanics aren't sound, the reporting layer won't rescue the experiment.
Common Control Group Pitfalls in CRO
Most failed experiments don't fail because the idea was bad. They fail because the comparison became contaminated, diluted, or unstable.
For reliable and repeatable results, the control group needs to stay large and stable, and teams should vary only one independent variable at a time so any measured change can be attributed with stronger internal validity, as noted in Cambridge Dictionary's definition of control group.
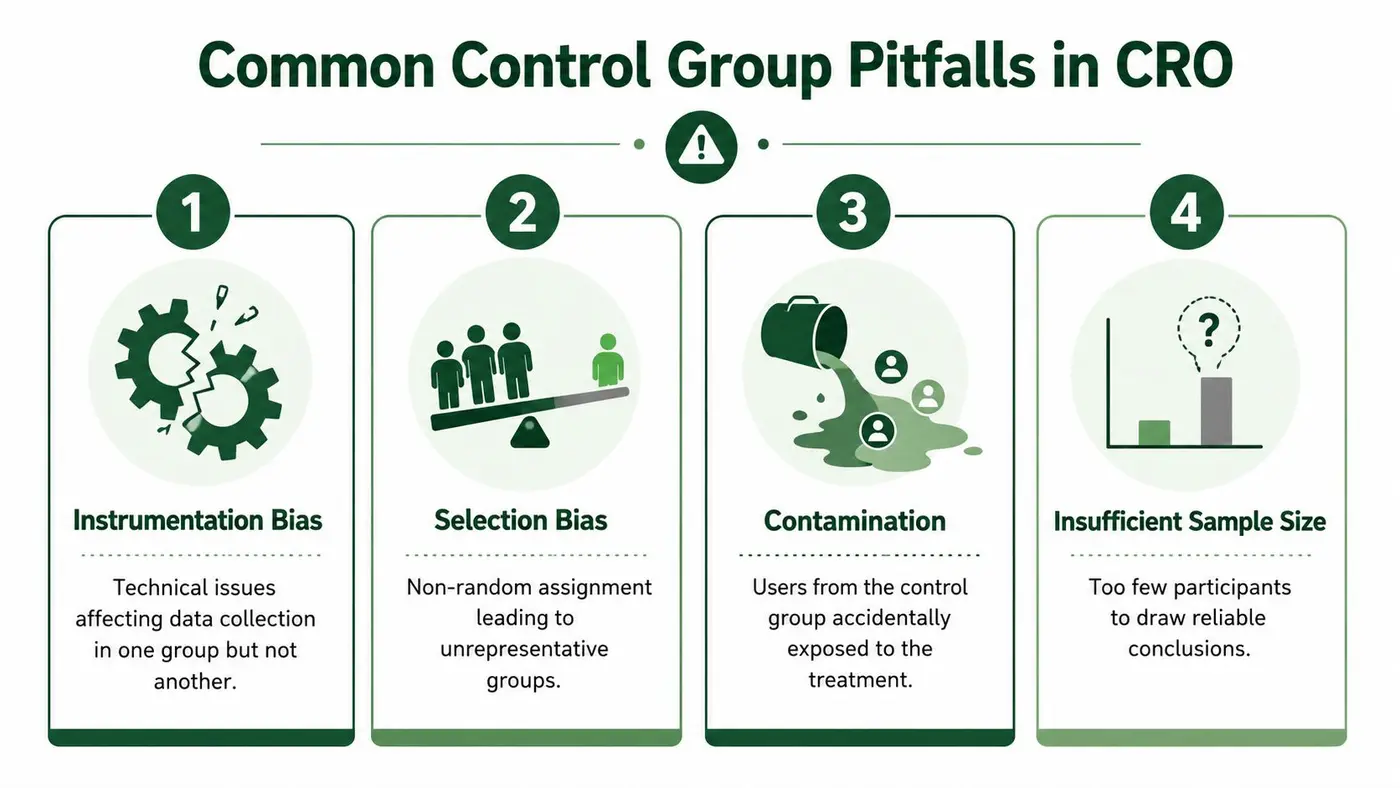
The mistakes that quietly ruin tests
Some pitfalls are obvious after the fact. Others look harmless in the moment.
- Changing the control mid-test: the product manager updates trust badges on Version A while the experiment is live. Now your baseline moved.
- Running too many variants on low traffic: each arm gets thinner, and the signal weakens.
- Ignoring contamination: users bounce between experiences because cookies reset or routing breaks.
- Stopping early because the graph looks good: that's one of the fastest ways to fool yourself.
Why “peeking” is such a problem
A dashboard can tempt you into acting too soon. The line goes up. The team gets excited. Someone says, “That's enough to call it.”
Usually, it isn't.
Early movement often disappears as more data comes in. That's one reason CRO teams spend so much time learning about false positives and missed effects. If you want a practical read on one side of that problem, this explanation of Type 2 errors in A/B testing helps clarify what happens when a test is too weak to detect a real difference.
A workable review checklist
Before you trust a test result, ask:
- Did the control stay unchanged for the full duration?
- Were users assigned cleanly without overlap or leakage?
- Was only one main variable changed between control and variant?
- Did each arm get enough traffic to support a meaningful read?
- Did we wait for the planned decision point instead of reacting to early noise?
If you're trying to build a broader optimisation programme, not just isolated tests, resources on how to turn more visitors into loyal customers can help frame experimentation inside the wider CRO workflow. Just keep the sequence right. Strategy first, baseline intact, interpretation second.
A messy control group doesn't create a small error. It changes what question your test is answering.
Frequently Asked Questions About Control Groups
Can you run an A/B test without a control group
Not really. You can run a before-and-after comparison, but that isn't the same thing as a proper A/B test. Without a live baseline running alongside the variant, you can't cleanly separate the impact of your change from everything else happening at the same time.
What's the difference between a control group and a control variable
A control group is a set of users or participants who receive the unchanged experience. A control variable is a factor you try to keep constant across groups, such as device conditions, offer structure, or timing. One is a group of people. The other is a condition you manage.
How long should you run a test with a control group
Run it until you reach the sample and decision criteria you set before launch, and long enough to cover normal business cycles. Don't stop because one line happens to be ahead on a given day. A weekday-heavy sample can tell a different story from a full cycle that includes your usual buying pattern.
Is the control group always the old version
Usually in CRO, yes. But not always. Sometimes the control is the current best-performing page, the standard onboarding flow, or the normal user experience already in place. The key idea is consistency. The control is the benchmark, not necessarily the oldest version.
What should you remember most
If you remember one thing, make it this: a control group is what lets you say your test result means something. It protects you from expensive confidence built on weak comparison.
If your team wants to run cleaner website experiments, Otter A/B is one option for setting up controlled tests on headlines, CTAs, and layouts without heavy implementation. It's built for teams that need a clear control, precise traffic splits, and readable results so decisions come from trustworthy comparisons rather than guesswork.
Ready to start testing?
Set up your first A/B test in under 5 minutes. No credit card required.